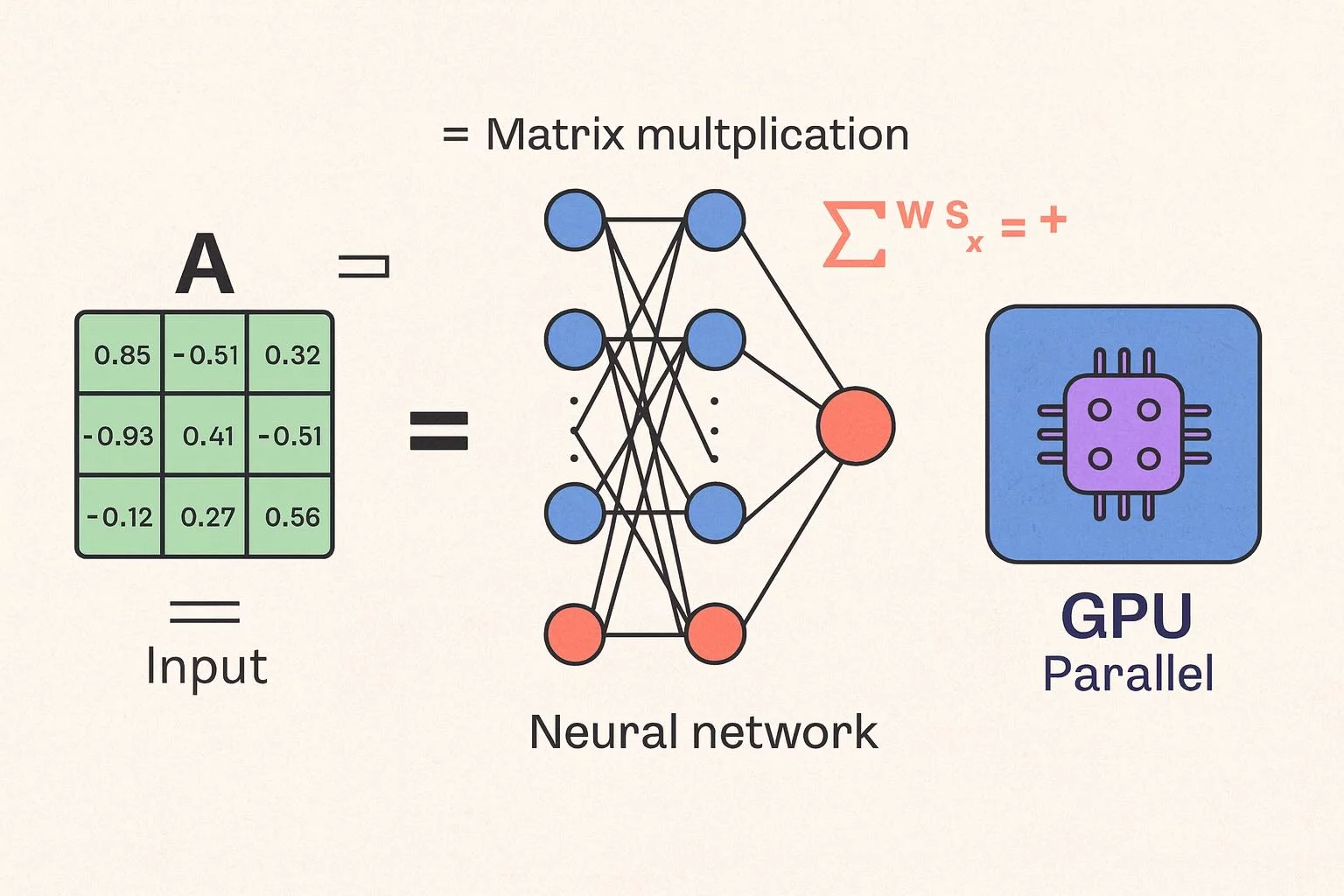
kali ini kita naik satu level: meniru kerja otak kecil, yaitu simulasi operasi
matrix multiplication seperti yang digunakan di neural network modern.Bayangkan kamu sedang melatih sebuah AI model. Setiap neuron di jaringan saraf akan mengalikan input dengan bobot tertentu, lalu menjumlahkannya.
Itulah yang kita uji di sini: seberapa cepat GPU di laptop/PC kamu mampu mengalikan ratusan angka sekaligus, secara paralel.

Apa yang akan kita test kali ini?
Test ini menjalankan operasi C = A × B pada dua matrix berukuran 64×64 (default), dengan aktivasi sederhana tanh().
Operasi ini adalah jantung dari model AI seperti GPT, Stable Diffusion, dan hampir semua sistem neural modern.
Kita tidak sedang menjalankan model AI sungguhan, tapi meniru salah satu langkah paling beratnya: matrix multiply.
Di GPU, ini dieksekusi oleh ratusan “thread” secara bersamaan lewat WebGPU compute shader.
💡 Catatan: Matrix multiply yang berukuran 64×64 saja sudah menghasilkan 262.144 operasi.
Kalau diulang misalnya 10 kali, maka GPU kamu akan melakukan lebih dari 2,6 juta operasi hanya dalam hitungan milidetik!
Sedikit Tentang Kode
Kode lengkapnya bisa kamu lihat di repository yang sudah saya tulis disini: github.com/mkhuda/webgpu-benchmark-js.
Berikut garis besar yang dijalankan di script ai-mini-benchmark.js:
- Membuat tiga buffer GPU:
A(input),B(bobot), danC(hasil). - Menulis shader WGSL yang berisi rumus perkalian dan penjumlahan matrix di GPU.
- Mengatur workgroup 8×8 — artinya 64 thread GPU bekerja bersamaan.
- Mengulang beberapa iterasi (misal 10 kali) untuk mengukur performa rata-rata.
- Menghitung hasil: waktu total (ms) dan perkiraan ops/second.
@compute @workgroup_size(8,8)
fn main(@builtin(global_invocation_id) gid : vec3) {
let N : u32 = 64u;
let row = gid.x;
let col = gid.y;
if (row >= N || col >= N) { return; }
var sum : f32 = 0.0;
for (var k = 0u; k < N; k++) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = tanh(sum);
}
Shader di atas adalah contoh “otak” kecilnya.
Setiap thread GPU mengambil satu baris dari A dan satu kolom dari B, lalu menghitung hasilnya ke C.
Fungsi tanh() memberi efek non-linear seperti neuron sungguhan.
Demo & Contoh Hasil
Silahkan lakukan demo disini untuk melihat hasil komputasi GPU kamu:
Live demo: WebGPU AI Mini benchmark langsung di browser
GPU: Apple M3 (Apple) Backend : WebGPU Matrix size : 64 x 64 Iterations : 10 GPU time : 214.526 ms Ops/Second : 1,209,326,194 Catatan: ini mensimulasikan operasi matrix multiply seperti layer neural network.
Semakin kecil waktu (
GPU time) dan semakin besarOps/Second, semakin efisien GPU kamu dalam menjalankan operasi AI.
🔍 Kenapa Matrix Multiply Itu Penting?
Di dalam model AI seperti ChatGPT, Stable Diffusion, atau bahkan asisten suara di HP kamu, hampir semua “keputusan” dibuat lewat operasi perkalian matrix.
Misalnya:
- Setiap token teks, diubah jadi vector (angka-angka).
- Vector ini dikalikan dengan matrix besar (bobot model).
- Hasilnya jadi input untuk lapisan berikutnya.
Semua langkah itu terjadi ribuan kali — itulah sebabnya GPU sangat penting.
GPU bisa memproses ratusan ribu operasi perkalian secara paralel,
sesuatu yang CPU tidak bisa lakukan dengan efisien.

Kesimpulan
Eksperimen mini ini bukan sekadar “benchmark lucu-lucuan”, tapi sebuah visualisasi nyata bagaimana browser kini bisa menjalankan simulasi AI compute di GPU tanpa library besar.
Dengan WebGPU, JavaScript bisa masuk ke ranah machine learning langsung dari browser.
Kedepannya, bukan tidak mungkin model-model kecil bisa dijalankan lokal,
tanpa harus upload data ke server.
💬 Jadi, benchmark ini bukan cuma mengukur kecepatan GPU kamu —
tapi bisa jadi, WebGPU bisa membuka jalan menuju masa depan AI di browser.
Terima kasih dan Stay tuned!
Tinggalkan Balasan