
Ketika membangun kamus kontemporer seperti ibahasa.com, saya tidak hanya terfokus pada bahasa gaul yang muncul di media sosial kemarin sore. Proyek ini punya misi besar untuk mendokumentasikan evolusi bahasa Indonesia, termasuk ejaan-ejaan legendaris seperti Van Ophuijsen dan Soewandi.
Masalahnya adalah data bahasa lama ini tidak semuanya tersedia dalam bentuk digital yang bersih. Banyak yang terkubur dalam lembaran kertas yang sudah menguning dan rapuh.
Untuk mengatasi ini, saya membangun alur kerja khusus yang menggabungkan metode konvensional dengan teknologi penglihatan komputer (Computer Vision).
Perburuan Literatur: Dari Tahun 1920 hingga 1972
Proses ini dimulai dari perburuan fisik di toko-toko buku lawas di Semarang. Saya berhasil mengamankan dua sumber literatur krusial yang menjadi “bahan bakar” utama leksikon tempo dulu di ibahasa.com:

Boekoe Soerat-Soerat oleh TH. A. Du Mosch (Cetakan Ketiga): Ini adalah permata dalam riset ibahasa. Buku ini terbit jauh sebelum Indonesia merdeka dan menggunakan ejaan Van Ophuijsen. Menariknya, buku ini menyajikan korespondensi dua bahasa: Belanda asli dan Indonesia gaya lama.

Buku kedua yang menjadi hidden gem adalah Bahasa Indonesia untuk SMP (Cetakan Kedua, 1972): Buku karya Drs. Soewandi dan Chaidir Anwar Said. Ini adalah rujukan utama saya untuk membedah Ejaan Soewandi (Ejaan Republik) yang populer sebelum pemberlakuan EYD.
Mengenal “ibahasa Vision”: Jembatan Analog ke Digital
Karena kondisi buku yang sudah sangat tua, saya tidak menggunakan pemindaian otomatis massal yang berisiko merusak fisik buku. Saya memilih metode kurasi manual yakni memotret bagian-bagian penting secara spesifik, lalu memprosesnya melalui ibahasa Vision.
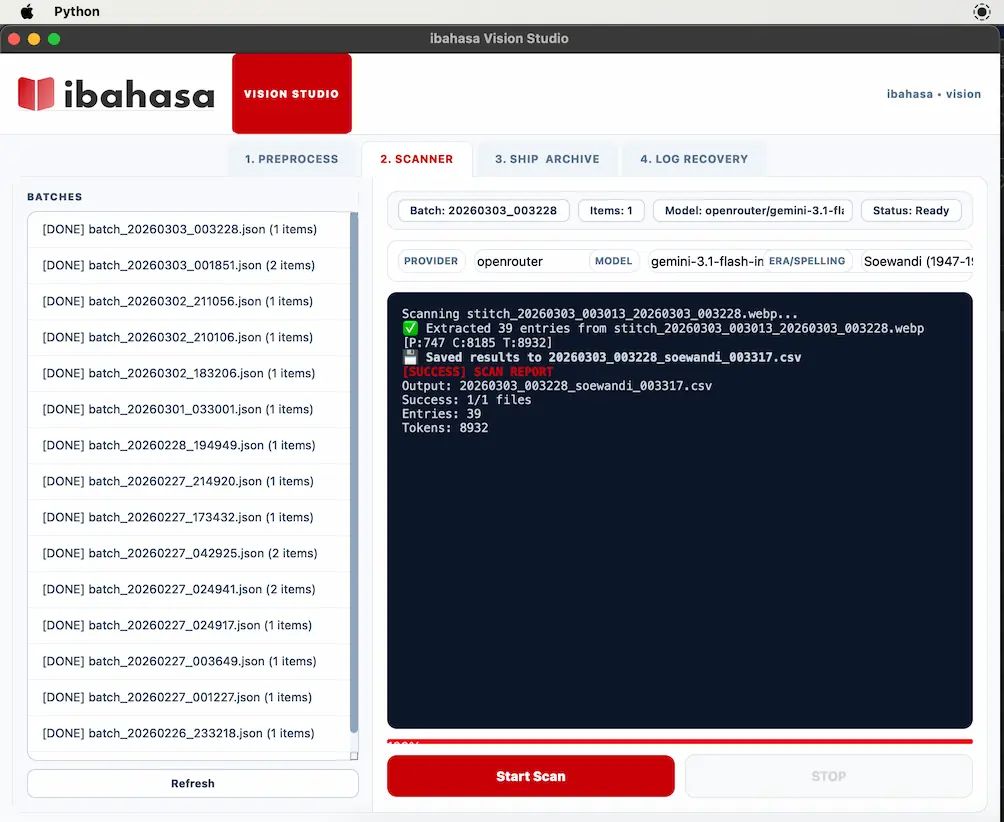
ibahasa Vision adalah internal tool berbasis Python Native App yang saya kembangkan khusus untuk kebutuhan ini. Alurnya adalah sebagai berikut:
- Ekstraksi Multi-LLM: Foto manual dari buku tersebut dilempar ke dalam sistem untuk diproses oleh berbagai model LLM terbaik.
- Best-of-Models: Memanfaatkan kekuatan Gemini, Claude, hingga model terbaru dari ByteDance via OpenRouter untuk mendapatkan ekstraksi teks yang paling presisi dari dokumen lama. Setiap model memiliki keunggulan dalam mengenali karakter cetakan tua yang sering kali pudar.
- Strukturisasi Data: Hasil ekstraksi tersebut kemudian diubah menjadi format CSV yang rapi untuk mempermudah pemetaan kata, makna, dan contoh penggunaan.
Integrasi ke Storage Server dan Admin Panel
Setelah data mentah dalam format CSV siap, langkah selanjutnya adalah menarik data tersebut langsung ke storage server ibahasa. Namun, proses tidak berhenti di sana. Karna teknologi ini hanyalah fasilitator, sedangkan filter terakhir tetaplah manusia.
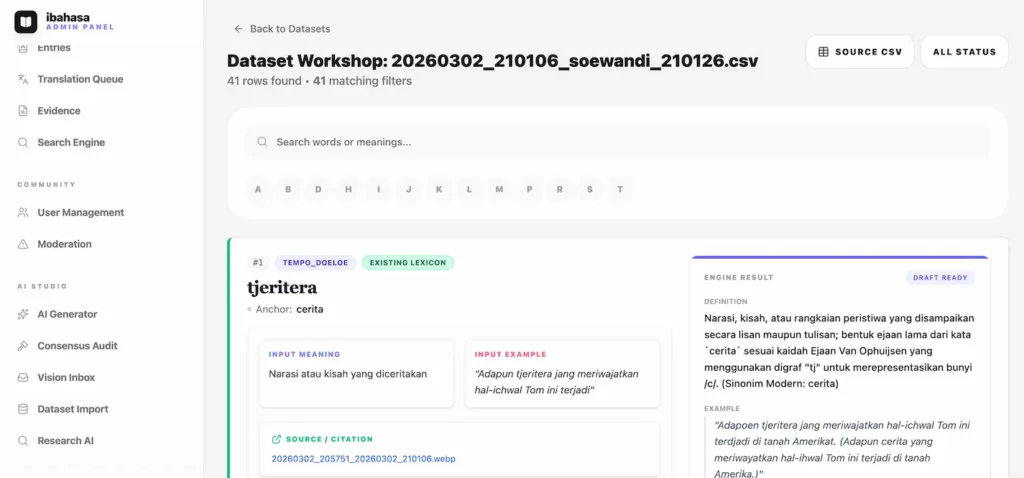
Data yang sudah diunggah akan masuk ke Admin Panel ibahasa untuk diproses secara semi-auto manual. Di sini, saya dan segelintir tim kurator melakukan pengecekan ulang:
- Memastikan tidak ada kesalahan pembacaan karakter (OCR misread).
- Memvalidasi konteks sejarah dari kata tersebut.
- Menyesuaikan format agar siap dikonsumsi oleh publik sebelum akhirnya statusnya berubah menjadi Published.
Validasi Berlapis via Integrasi LLM Lanjutan dan Consensus AI
Meskipun data berasal dari sumber literatur primer yang valid, saya tidak membiarkan proses input berjalan secara manual sepenuhnya. Setiap leksikon yang berhasil diekstraksi dari buku-buku tua tersebut akan melewati fase pengujian ulang melalui sistem Consensus AI (baca disini detail-nya).
Langkah ini krusial untuk memastikan hasil yang lebih sempurna:
- Verifikasi Lintas Model: Leksikon akan dicek kembali menggunakan beberapa LLM sekaligus untuk memvalidasi apakah makna yang diekstraksi sudah konsisten secara linguistik.
- Akurasi Kontekstual: Sistem Consensus membantu mendeteksi jika ada anomali pada hasil ekstraksi awal, sehingga kurator manusia hanya perlu fokus pada detail-detail yang memang memerlukan diskursus mendalam.
- Otomasi Terukur: Dengan melibatkan kecerdasan kolektif dari berbagai model AI, risiko kesalahan penafsiran pada ejaan lama (seperti perbedaan tipis pada tipografi cetakan 1920-an) bisa diminimalisir secara signifikan sebelum masuk ke tahap publishing.
Memang, tidak semua Lemma di ibahasa menggunakan Consensus, karna metode ini cukup menguras cost dan memakan waktu. Bayangkan jika ada 1000 lemma dan harus dikurasi. Untuk hal ini, ketelitian manusia lebih cepat dan efisien dibanding processing via LLM.
Penggabungan antara data historis yang otentik dengan sistem audit modern ini memastikan bahwa setiap kata di ibahasa.com memiliki standar akurasi yang dapat dipertanggungjawabkan.
Menjaga Warisan yang Hampir Terlupakan
Apa yang dilakukan melalui ibahasa Vision adalah upaya untuk memastikan bahwa kekayaan linguistik kita tidak hilang dimakan usia. Dengan mendigitalisasi buku-buku tua ini, ibahasa.com mencoba memberikan kesempatan bagi generasi sekarang untuk memahami bagaimana kakek-nenek kita berkomunikasi di masa lalu.
Bahasa Indonesia adalah identitas yang terus berevolusi, dan melalui platform ini, kita bisa melihat jejak evolusi tersebut dengan jelas, satu kata demi satu kata. 🚀🚀
Tinggalkan Balasan